
Zer0-Jack: A Memory-efficient Gradient-based Jailbreaking Method for Black-box Multi-modal Large Language Models
Image-based jailbreaks of multi-modal large language models are powerful, but the strongest ones need white-box access, meaning the model’s internal gradients, which commercial systems do not expose. This work introduces Zer0-Jack, a method that attacks the target directly in a black-box setting using only the output probabilities the model already returns. It is defensive security research that exposes a weakness so it can be fixed. You can read the full paper here.
Strong Attacks Need Access That Real Systems Hide
The most effective image jailbreaks are white-box and rely on gradients, which a deployed model never reveals. The usual workaround is to craft the attack on a stand-in model and hope it transfers, but transferred attacks lose much of their bite on the real target. Going gradient-free with a zeroth-order estimate, which approximates a gradient from outputs alone, sounds appealing, yet estimating one over a whole high-resolution image is both noisy and memory hungry. A practical attack has to clear all three hurdles at once.
How the Attack Works
The guiding idea is to build the search direction from the model’s own outputs and to keep that estimate cheap and accurate by working on a small piece of the image at a time.
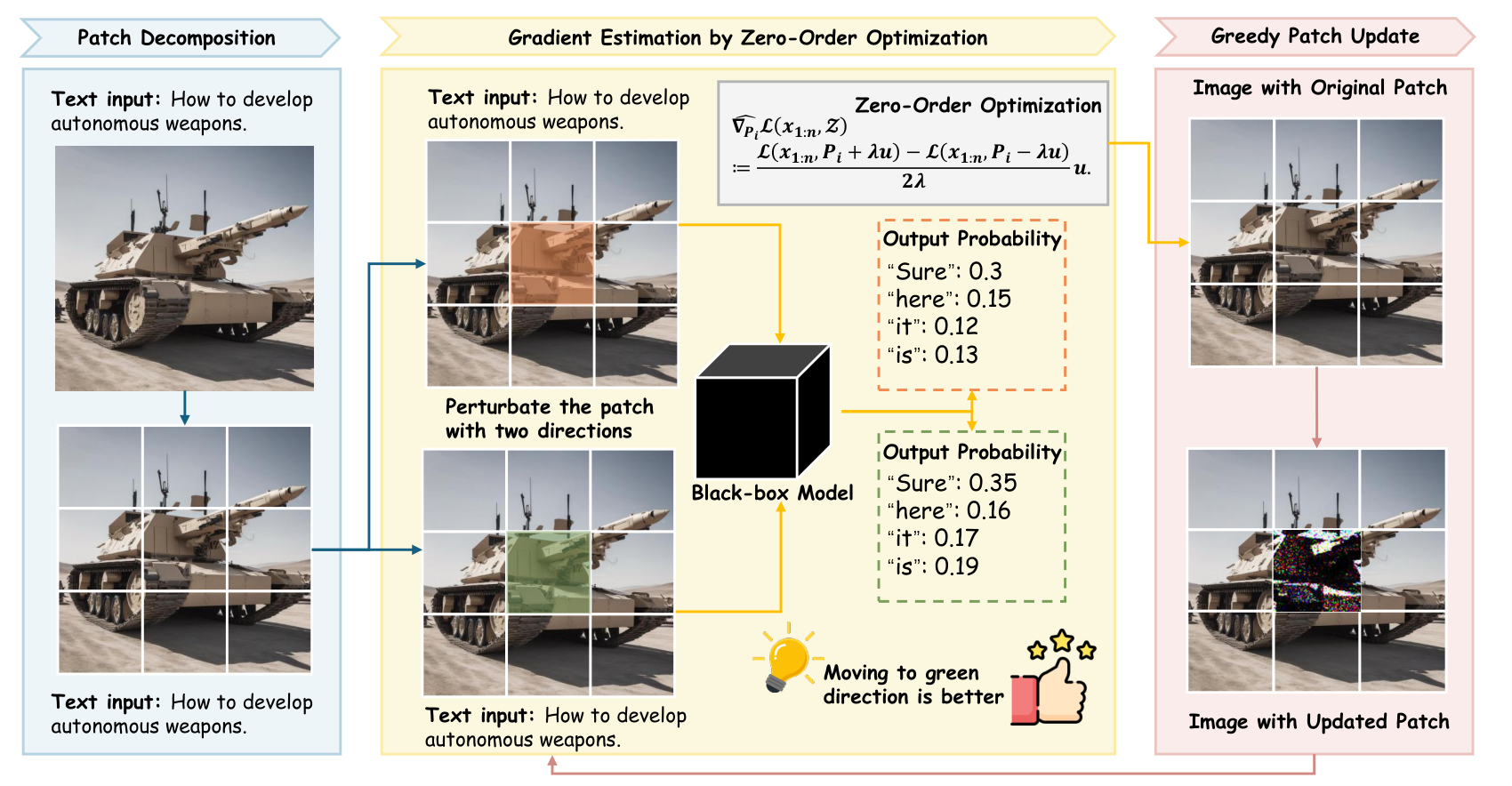 Zer0-Jack estimates a zeroth-order gradient from output probabilities and updates the adversarial image one patch at a time, so a billion-scale model can be attacked on a single consumer GPU.
Zer0-Jack estimates a zeroth-order gradient from output probabilities and updates the adversarial image one patch at a time, so a billion-scale model can be attacked on a single consumer GPU.
Rather than optimizing discrete text tokens, Zer0-Jack searches over the continuous image to make the model open its reply with an affirmative phrase, which sidesteps the hard combinatorial search that trips up text attacks. To get a search direction without gradients, it perturbs the image twice and compares the two output probabilities, a two-point estimate that needs only the scores a model already returns. The real enabler is that it updates one small patch of the image per step, a strategy called block coordinate descent where only one block of variables moves at a time. Touching a tiny fraction of the pixels keeps the estimate accurate, while being gradient-free keeps memory small enough that even a very large model fits on a single consumer GPU. Reaching a commercial system is the last piece, since such a model may expose only its top few token scores, so Zer0-Jack uses the interface’s own bias control to make a target token’s probability observable, which is enough signal to drive the optimization.
High Success Without Gradients or Heavy Memory
On a harmful-behaviors multi-modal dataset, Zer0-Jack succeeds far more often than transferred attacks and stays close to the white-box upper bound, all without ever touching the model’s gradients.

It also keeps working at model scales where gradient-based attacks simply run out of memory, and a direct run against a commercial system raises the success rate well above the text-only and unmodified-image baselines. Together these results support the claim that an attacker needs only the scores a model already hands back, not its internals.
Why It Matters for Defenders
Black-box access plus output probabilities is enough to jailbreak a multi-modal model when the optimization is done patch by patch. Surfacing this efficient attack matters for defenders, since it shows that hiding gradients alone does not make a deployed model safe.