
Vision Language Model Helps Private Information De-Identification in Vision Data
Sensitive text often lives inside image pixels, for example a patient name printed on a medical scan, and prior de-identification work mostly blurs faces and ignores this text. This work reframes the task as selective optical character recognition (OCR), the reading of text from an image, driven by an instruction that says what counts as private. The framework is called VisShield. You can read the full paper here.
Private Text Hidden in Image Pixels
Vision language models inherit the privacy risks of the language models inside them, and one overlooked surface is text printed directly into an image. Earlier image de-identification work almost always targets faces, and the one existing tool for textual de-identification, Presidio, cannot be told what should count as private and does poorly in practice. The task really needs two things at once, locating the sensitive text and then removing it, under a notion of private that each user or domain can define.
De-Identification as Selective, Instruction-Driven OCR
The key idea is that a model which already reads text in images can be taught to extract only the privacy relevant parts, and because the definition of private information lives in the instruction, the same model serves very different policies without retraining.
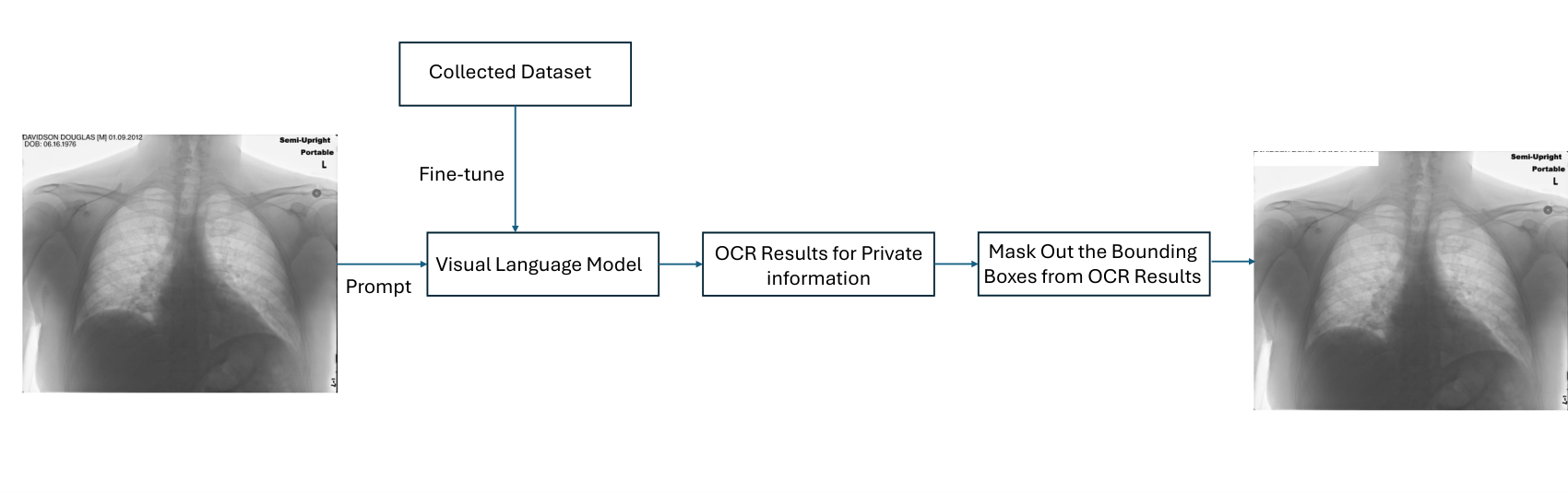 An instruction-tuned vision language model performs privacy-aware OCR, locating only the sensitive fields, then each detected box is masked by filling it with its corner pixel color.
An instruction-tuned vision language model performs privacy-aware OCR, locating only the sensitive fields, then each detected box is masked by filling it with its corner pixel color.
The instruction defines what is private. Each prompt spells out the definition of private information, gives a few worked examples to cover format variation, and uses a standard token that signals privacy-aware reading, across categories such as name, social security number, address, and medical numbers. Putting the definition in the prompt is what lets one model serve a hospital and a bank differently, since each can ask for different things and nothing is retrained.
Training data is synthetic, with answers for free. The authors build a dataset called OPTIC by overlaying realistic fake private information onto natural and medical images with randomized fonts, sizes, and colors. Generating it synthetically pays off twice, because it produces exact ground-truth boxes automatically and avoids handling real personal data, while the randomization forces the model to generalize past any single layout. Crucially, any prompt can be paired with any image, and the label contains boxes only for the types that prompt names, which teaches the model to surface the sensitive fields and ignore the rest.
A reader is fine-tuned, then the output is masked. The OCR-capable model Kosmos-2.5 is fine-tuned on this data, comparing full fine-tuning against LoRA, a lightweight scheme that updates only a small set of added weights, so the only thing the model learns is selectivity rather than reading from scratch. At inference it returns boxes for the defined fields and each box is masked by filling it with its corner color.
Accurate, Flexible Masking Where Presidio Fails
Across four different image sources, the fine-tuned model both finds and isolates the sensitive text with high quality, and it transfers to images, and even to information types, it never saw in training rather than overfitting one layout.
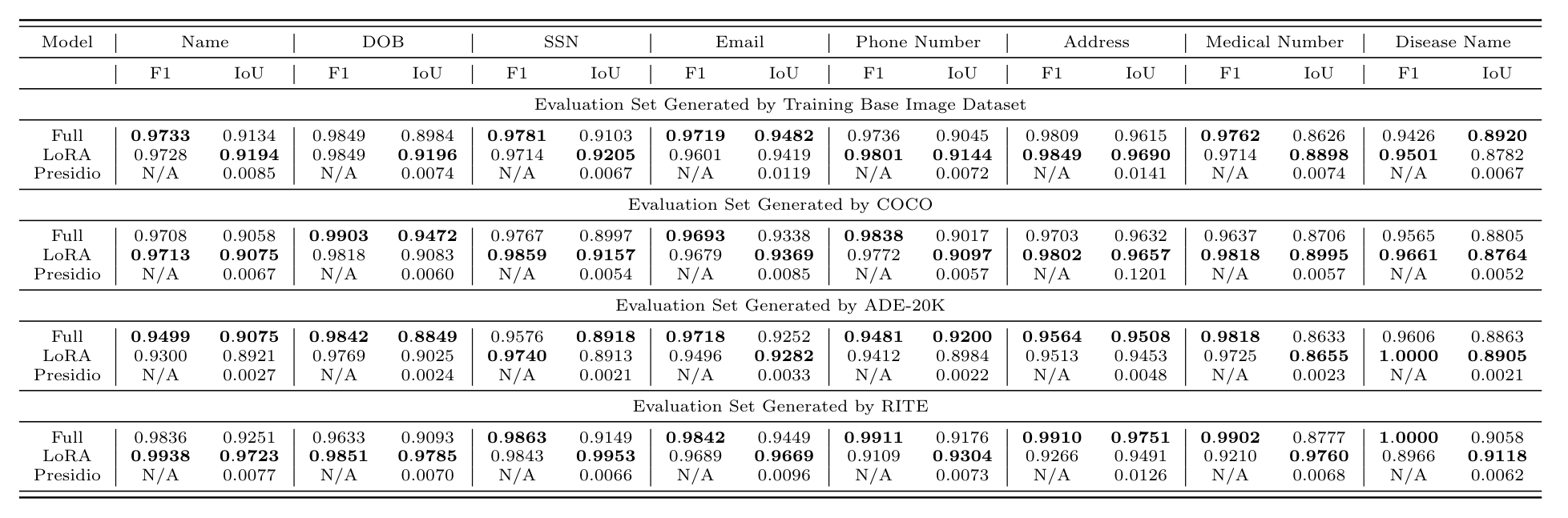
The contrast with Presidio is stark, since that tool barely localizes the private text at all. This supports the central claim that framing de-identification as instruction conditioned OCR, rather than fixed recognizers, is what makes flexible and reliable masking possible.
Takeaway
Treating de-identification as instruction-driven selective OCR lets one fine-tuned vision language model both find and isolate sensitive text in images, with a flexibility and accuracy that fixed tools cannot reach.