
Position: Uncertainty Quantification in LLMs is Just Unsupervised Clustering
Before we trust a large language model in a hospital or a courtroom, we want it to tell us how sure it is. Uncertainty quantification, the family of methods that turn a model’s outputs into a confidence score, is meant to provide that safety check. This position paper argues that the safety check is an illusion, because most of these methods are mechanically the same as unsupervised clustering, a technique that groups data by similarity without ever consulting a correct answer. You can read the full paper here.
Why Today’s Confidence Scores Are Risky
The appeal of uncertainty quantification is simple. If a model can flag the answers it is unsure about, a person can step in before a mistake causes harm. The problem is what these scores actually measure. They look at how much a model’s own repeated answers agree with each other, not at whether those answers are true. A model can give the same wrong answer every time, look perfectly consistent, and earn a high confidence score. The paper calls this a confident hallucination, and it is exactly the failure a safety check is supposed to catch.
The Hidden Equivalence Behind the Scores
Once you ask what each method computes, the resemblance to clustering is hard to unsee. Semantic entropy groups a model’s sampled answers into clusters of shared meaning and calls a question uncertain when those answers scatter across many clusters. Graph-based methods build a similarity graph over the answers and read its structure, which is clustering by another name. Verbalized confidence, where the model is simply asked how sure it is, partitions the model’s own internal states into confident and unconfident regions. In every case the score reflects the shape of the model’s answer distribution, never its distance from the truth.
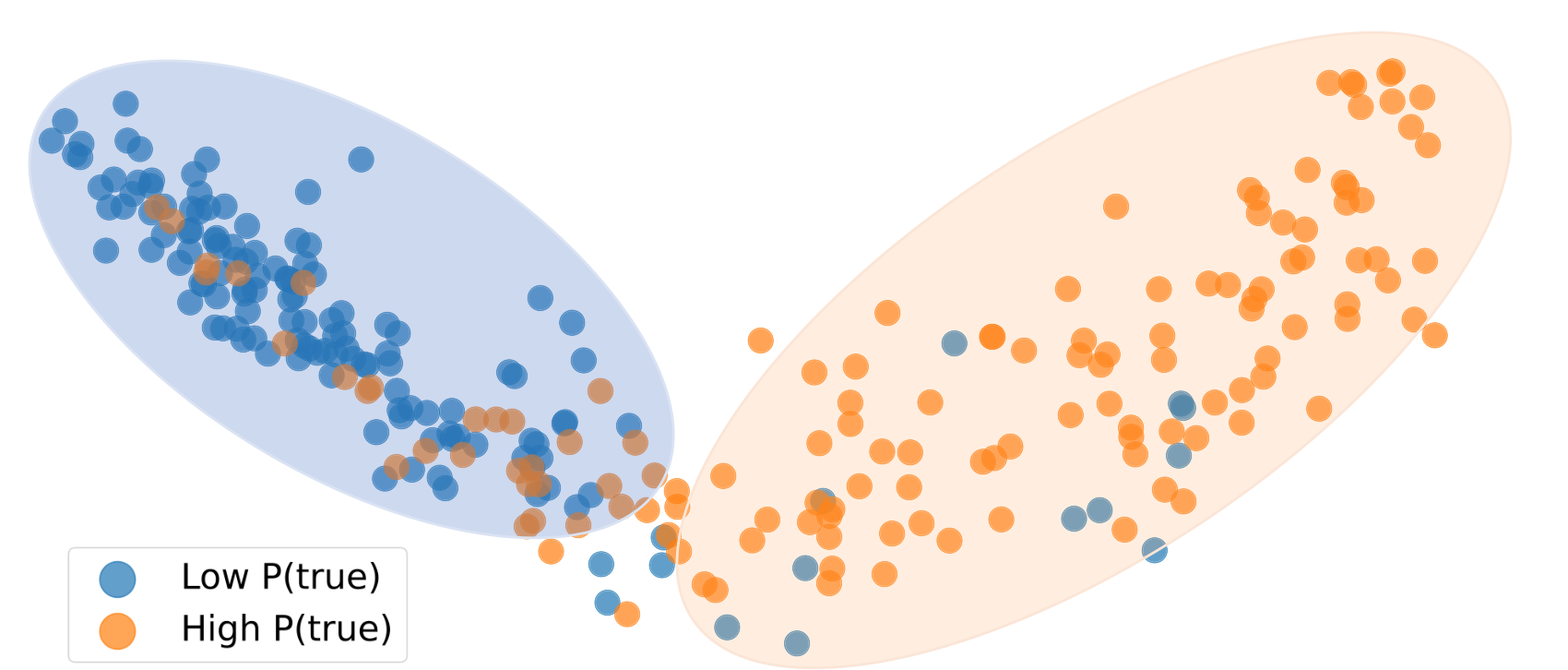 When the model’s internal states are projected down to two dimensions, the high-confidence and low-confidence answers fall into separate groups. The method is sorting its own outputs into clusters, not checking them against reality.
When the model’s internal states are projected down to two dimensions, the high-confidence and low-confidence answers fall into separate groups. The method is sorting its own outputs into clusters, not checking them against reality.
Where the Clustering View Goes Wrong
Treating internal agreement as if it were correctness creates three concrete failures.
- The scores are fragile. They shift with the number of samples drawn, the similarity threshold, the decoding temperature, and the prompt. Worse, different methods disagree about which answers count as uncertain, so there is no stable notion of uncertainty to begin with.
- Evaluation rewards the wrong thing. Because correctness is hard to measure, the field grades uncertainty by how self-consistent a model is, which quietly equates stability with truth and lets confident hallucinations pass.
- There is no ground truth to anchor on. Real uncertainty is unobservable, so studies lean on other language models to judge correctness, which creates a loop where one model’s confidence is validated by another model’s opinion.
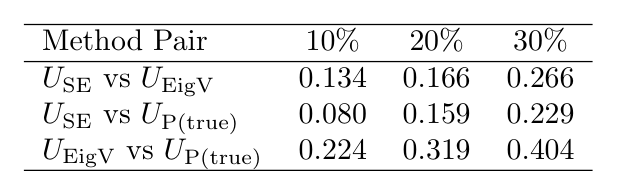
The first failure is easy to see directly. When several methods each flag the answers they consider most uncertain, the overlap between their flagged sets is small, which means they are not measuring one shared thing.
A Way Forward: Grounding Uncertainty in Truth
The paper’s prescription is to stop optimizing internal agreement and start measuring against reality, along three lines. Evaluation should report worst-case behavior and how stable a score is, rather than a single average. Mechanisms should give native guarantees, for example conformal prediction, a procedure that returns a set of answers guaranteed to contain the correct one at a chosen rate, so a confident hallucination shows up as an unusually large set. And verification should be anchored in objective truth, through unit tests in code and math or fact checking against trusted sources, instead of asking another model to be the judge.
Takeaway
A confidence score that never looks at the right answer is measuring consensus, not correctness. Until uncertainty quantification is grounded in external truth, a high score tells us only that a model is consistent, which is not the same as telling us it is right.