
Privacy-Preserving Large Language Models via Flatness-Aware Fine-Tuning
Large Language Models (LLMs) have become increasingly prevalent in various applications, but their potential to memorize sensitive training data raises significant privacy concerns. This paper introduces Privacy-Flat, a novel framework designed to improve the privacy-performance trade-off in LLMs by focusing on the flatness of the loss landscape during fine-tuning.
The Challenge: Privacy vs. Performance
Traditional methods to protect privacy in LLMs, like Differential Privacy (DP) techniques such as DP-SGD, often lead to a noticeable drop in model performance. As shown in Figure 1, DP-trained models tend to have a sharper loss landscape, meaning that small changes to model weights can drastically impact performance. This paper explores the idea that a flatter loss landscape can simultaneously enhance privacy and generalization ability.
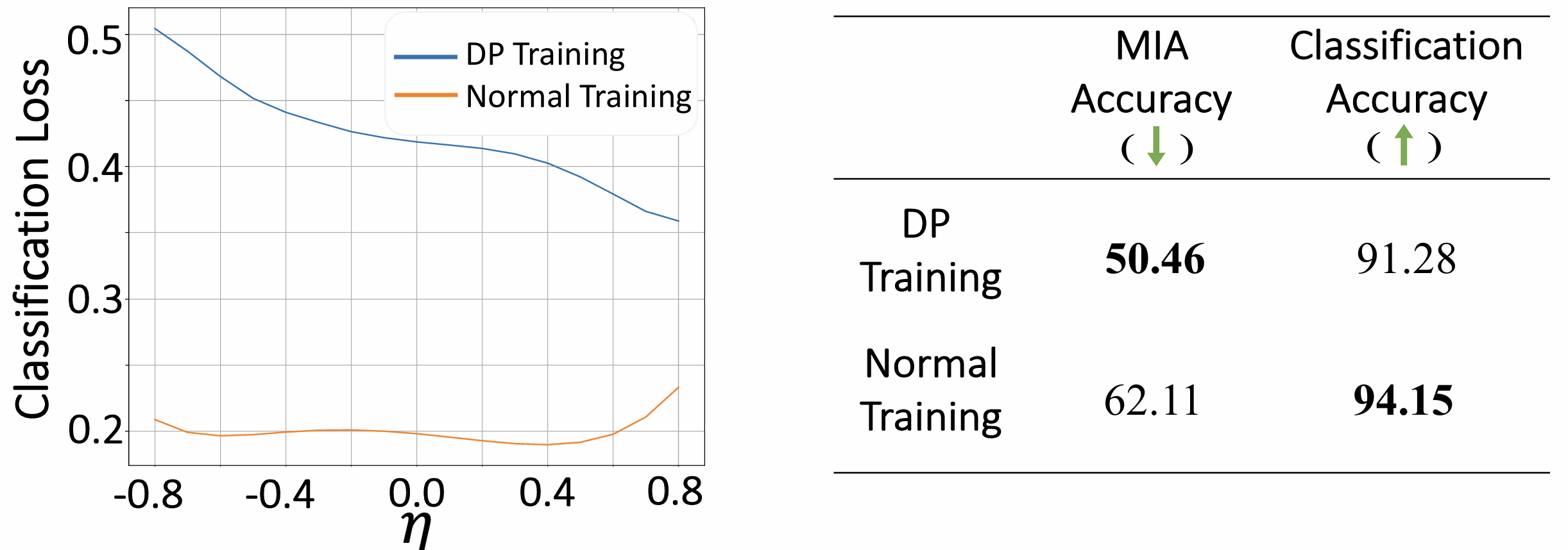 Figure 1: Sharp vs. Flat Loss Landscapes
Figure 1: Sharp vs. Flat Loss Landscapes
Privacy-Flat: A Holistic Approach
The core idea of Privacy-Flat is to enforce appropriate weight flatness through a multi-faceted approach. It innovates from three levels:
1. Within-layer Flattening
- Uses a perturbation-aware min-max optimization to encourage loss flatness within each LLM layer.
- Achieved by applying adversarial weight perturbation (AWP) during the initial training rounds, which helps guide the model towards a smoother loss region.
2. Cross-layer Flattening
- Employs a sparse prefix-tuning algorithm to guide layer selection using a flatness-aware indicator.
- By calculating the “sharpness” of the loss landscape after removing prefix layers, the algorithm retains only the most useful prefix layers for flatness.
3. Cross-model Flattening
- Leverages non-private prefixes to guide DP-SGD training through knowledge distillation regularization with non-private weights.
- Involves training a non-private duplicate of the model and using it to regularize the private model’s training, encouraging weight closeness.
These strategies work together to smooth the sharp local minima that often result from DP training. Figure 2 illustrates the three components of the Privacy-Flat framework.
 Figure 2: Privacy-Flat Framework
Figure 2: Privacy-Flat Framework
The result is a flatter loss landscape, as seen in Figure 3, achieved by integrating the proposed weight flattening methods with DP-trained prefix tuning.
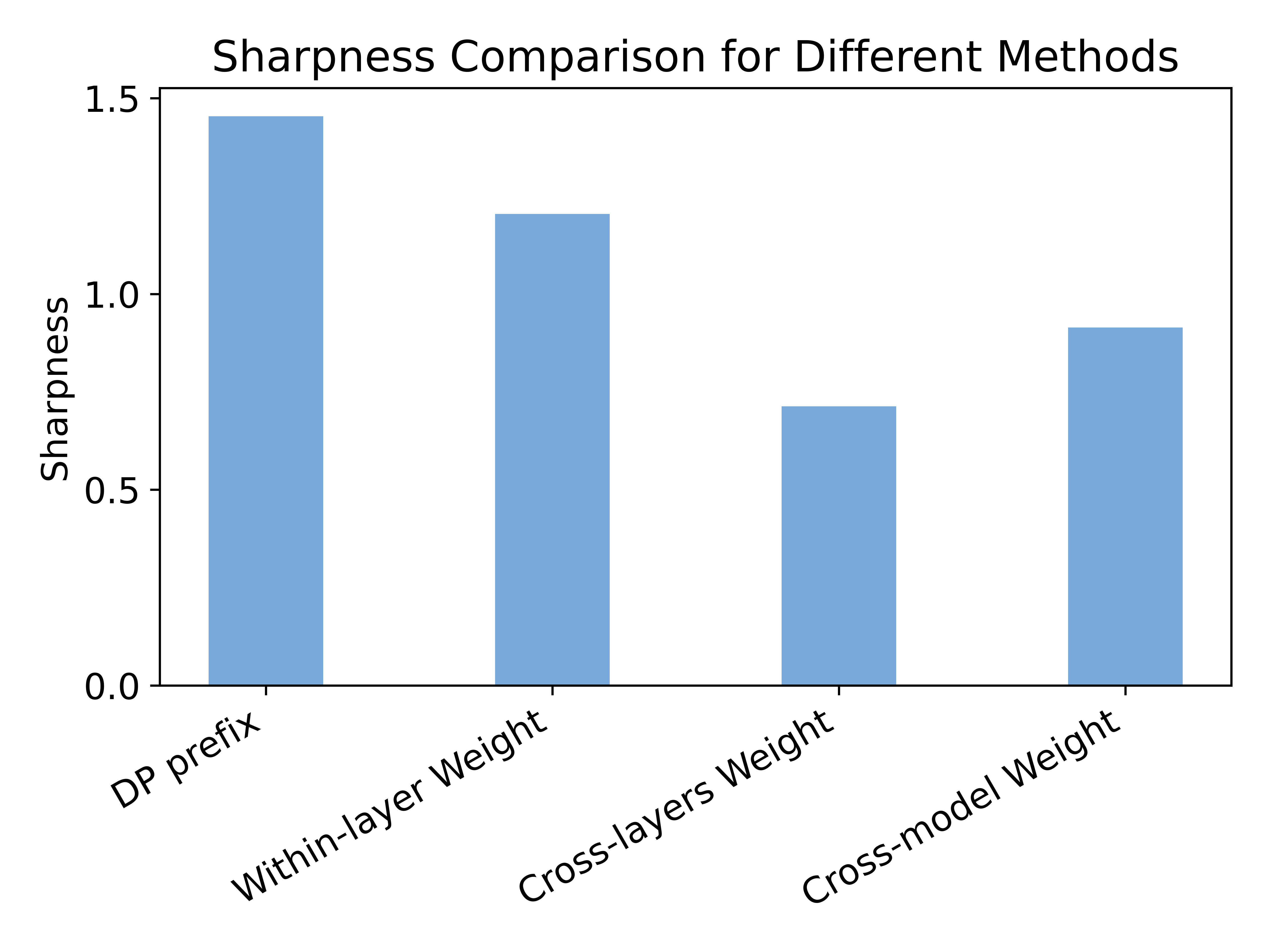 Figure 3: Flatter Loss Landscape Achieved
Figure 3: Flatter Loss Landscape Achieved
Key Findings
Comprehensive experiments were conducted in both white-box (where the model’s internal parameters are accessible) and black-box (where they are not) settings, demonstrating that Privacy-Flat can:
- Improve model performance in various NLP tasks, including text classification and text generation. In some cases, Privacy-Flat even outperforms non-private fine-tuning.
- Maintain strong privacy protection, comparable to traditional DP methods. As shown in Figure 4, the Membership Inference Attack (MIA) accuracy is similar to that of DP-trained models, indicating that Privacy-Flat does not compromise privacy.
 Figure 4: Membership Inference Attack Accuracy
Figure 4: Membership Inference Attack Accuracy
- Bridge the performance gap between private and non-private LLMs, especially under the white-box setting. In the black-box setting, the performance gap is bigger, but Privacy-Flat still shows better accuracy under the privacy setting.
Implications
This work highlights the importance of considering the loss landscape in the design of privacy-preserving machine learning algorithms, offering a new approach to improve the performance of DP-trained LLMs. The authors also provide a pioneering framework for closed-source LLMs, where access to internal parameters is limited.
Future Work
While Privacy-Flat shows promise, the authors acknowledge that the method does not provide a strict DP guarantee like traditional DP-SGD. Future work will:
- Explore the theoretical underpinnings of why Privacy-Flat maintains good privacy.
- Further refine its effectiveness in real-world applications.