
Uncertainty Quantification of Large Language Models through Multi-Dimensional Responses
Every uncertainty quantification method for LLMs looks at one signal, yet a fluent answer can still be wrong, so any single signal gives an incomplete picture. This work introduces MS-UQ, a black-box framework that combines several heterogeneous uncertainty signals into one score without letting redundant agreement dominate. You can read the full paper here.
The Challenge: Each Signal Tells Only Part of the Story
Different uncertainty sources, such as semantic entailment, response graph statistics, and claim level factual consistency, each capture one facet of why a model might be unsure. The trouble is that they also overlap heavily, so naively averaging or concatenating them mostly recounts the same shared agreement and drowns out the disagreements that actually signal risk. A good framework therefore has to separate what the sources share from what each one uniquely contributes, and it should stay open to new sources without being redesigned.
MS-UQ: Fusing Uncertainty Sources with a Tensor
The guiding idea is that consistent responses share a simple low rank structure, while genuine disagreement does not, so how hard the signals are to compress becomes a measure of uncertainty.
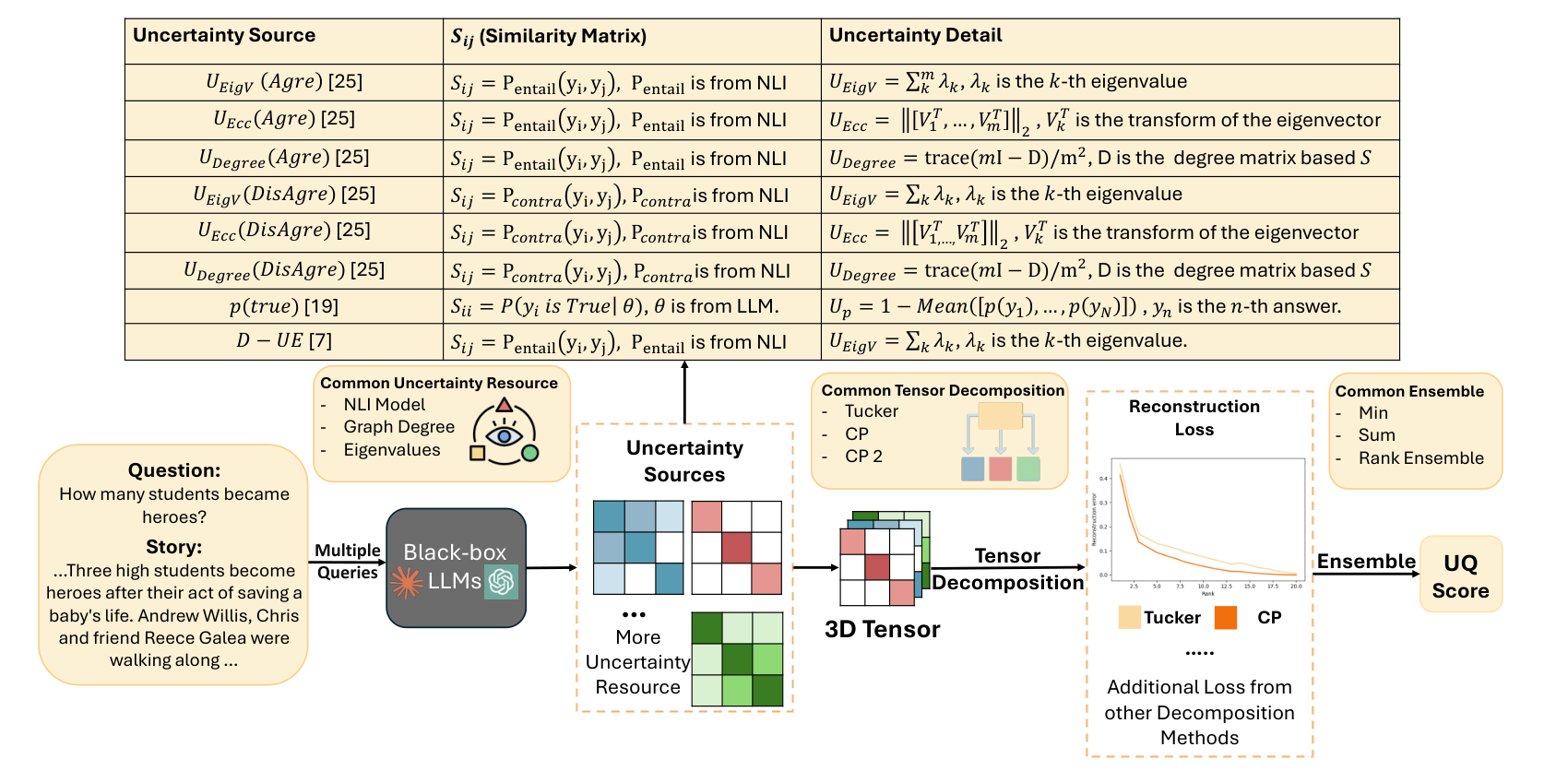 Each uncertainty source becomes a response by response similarity matrix, the matrices stack into a third order tensor, and tensor decomposition separates shared from source specific structure so reconstruction error reads out as uncertainty.
Each uncertainty source becomes a response by response similarity matrix, the matrices stack into a third order tensor, and tensor decomposition separates shared from source specific structure so reconstruction error reads out as uncertainty.
Turn each signal into a similarity matrix
For a question, MS-UQ samples several responses and, for every source, builds a response by response similarity matrix. Working with similarities rather than raw scores puts every heterogeneous source onto the same footing, so a semantic signal and a factual signal can later be combined without hand tuned weights.
Stack the matrices instead of concatenating them
Concatenation lets the redundant, shared part of the sources dominate and hides their differences, which is exactly the information MS-UQ wants. Instead the matrices are stacked as parallel slices of a third order tensor, which keeps each source on its own axis. This preserves what is unique to each source so that a disagreement visible in only one of them is not averaged away.
Decompose two complementary ways
The tensor is factorized with both a Tucker and a CP decomposition. Tucker is expressive and captures rich interactions between sources, while CP is simpler and more robust to noise, so running both hedges against the blind spots of either. The source axis is left uncompressed on purpose, which guarantees that source specific structure is never collapsed during the fit.
Read uncertainty from how well it compresses
Responses that agree reconstruct almost perfectly from a low rank fit, while responses that disagree across sources leave a large residual. MS-UQ uses that relative reconstruction error, summed across ranks so it does not hinge on one rank choice, as the uncertainty score, and an analysis links more source disagreement to a larger residual. The Tucker and CP scores are merged with a tuning free rule, which means a new uncertainty source can be dropped in later without retraining or redesign.
A Stronger Signal, Especially When Reasoning Is Hard
Tested across five models on three question answering datasets, MS-UQ separates correct answers from incorrect ones more reliably than every single source baseline it is built from, which shows the fusion adds real information rather than reshuffling what each source already knew.
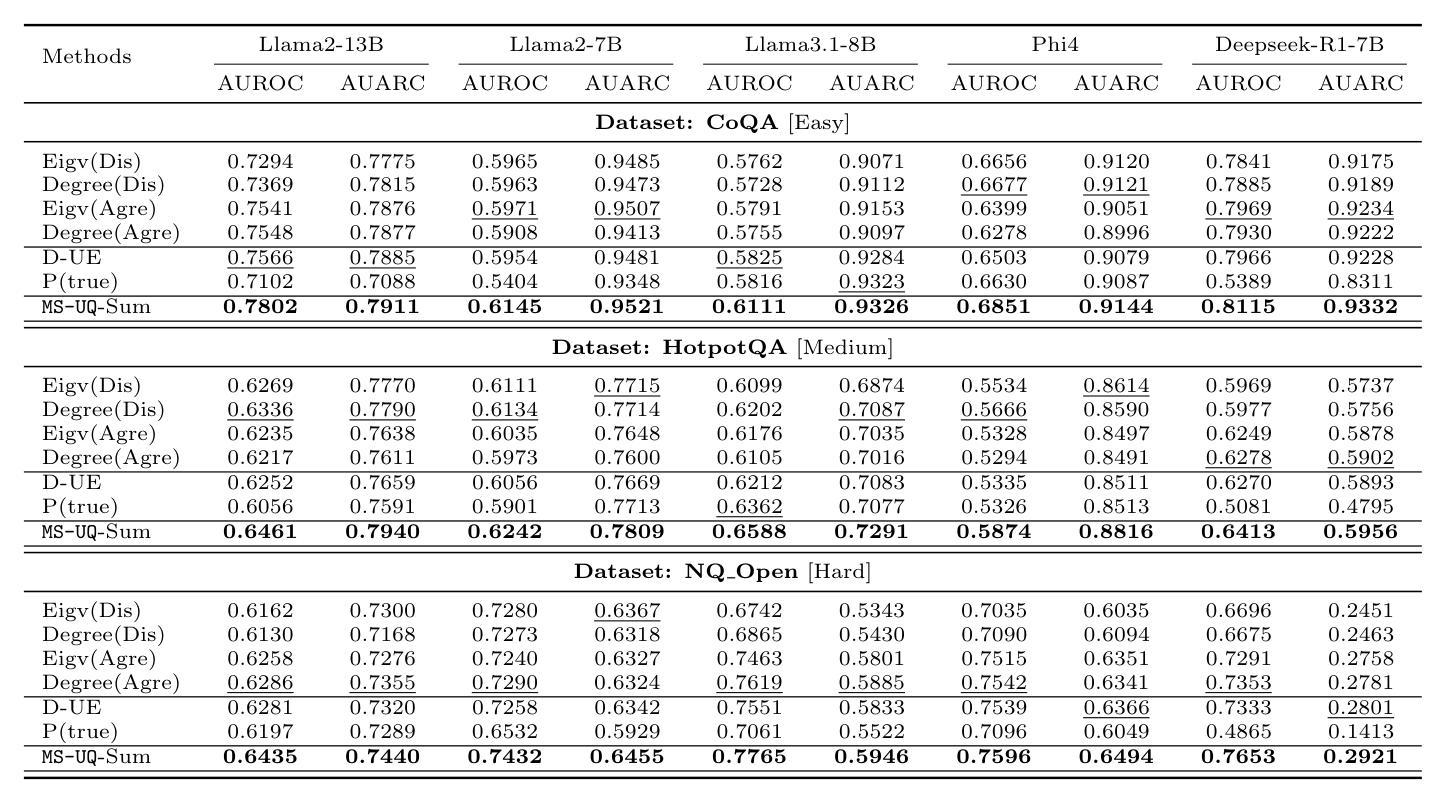
The advantage is widest on the multi-hop reasoning dataset, where combining complementary views matters most. A supporting analysis confirms the mechanism behind the score, since answers the model gets right consistently leave a smaller reconstruction residual than answers it gets wrong.
Takeaway
Uncertainty signals are complementary but redundant, so they should be disentangled rather than averaged. A tensor over sources, read through its reconstruction error, fuses them into one scalable score that beats every single source baseline.