
Every Response Counts: Quantifying Uncertainty of LLM-based Multi-Agent Systems through Tensor Decomposition
LLM multi-agent systems beat single agents on hard tasks, yet we still cannot tell when their answers are trustworthy. This work introduces MATU (Multi-Agent Tensor Uncertainty), a framework that measures uncertainty directly from the full reasoning trajectories of a multi-agent system rather than from its final text. You can read the full paper here.
Why Single-Answer Uncertainty Breaks Down for Agent Teams
Existing uncertainty quantification was built for one model answering one question once, and it usually compares only final answers. A multi-agent system is different in three ways that this view cannot see. Its reasoning unfolds over many steps, so an early mistake can quietly cascade into a confident but wrong outcome, which is dangerous in high-stakes settings like healthcare. Its agents exchange information along paths that change from run to run. And it can be wired into different topologies such as star, chain, or dynamic routing. Reading only the last sentence discards exactly the structure that decides whether the system is reliable.
How MATU Measures It
The guiding intuition is that a reliable system reaches the same place through similar reasoning, so its repeated runs share a common low rank structure, and whatever refuses to fit that structure is uncertainty.
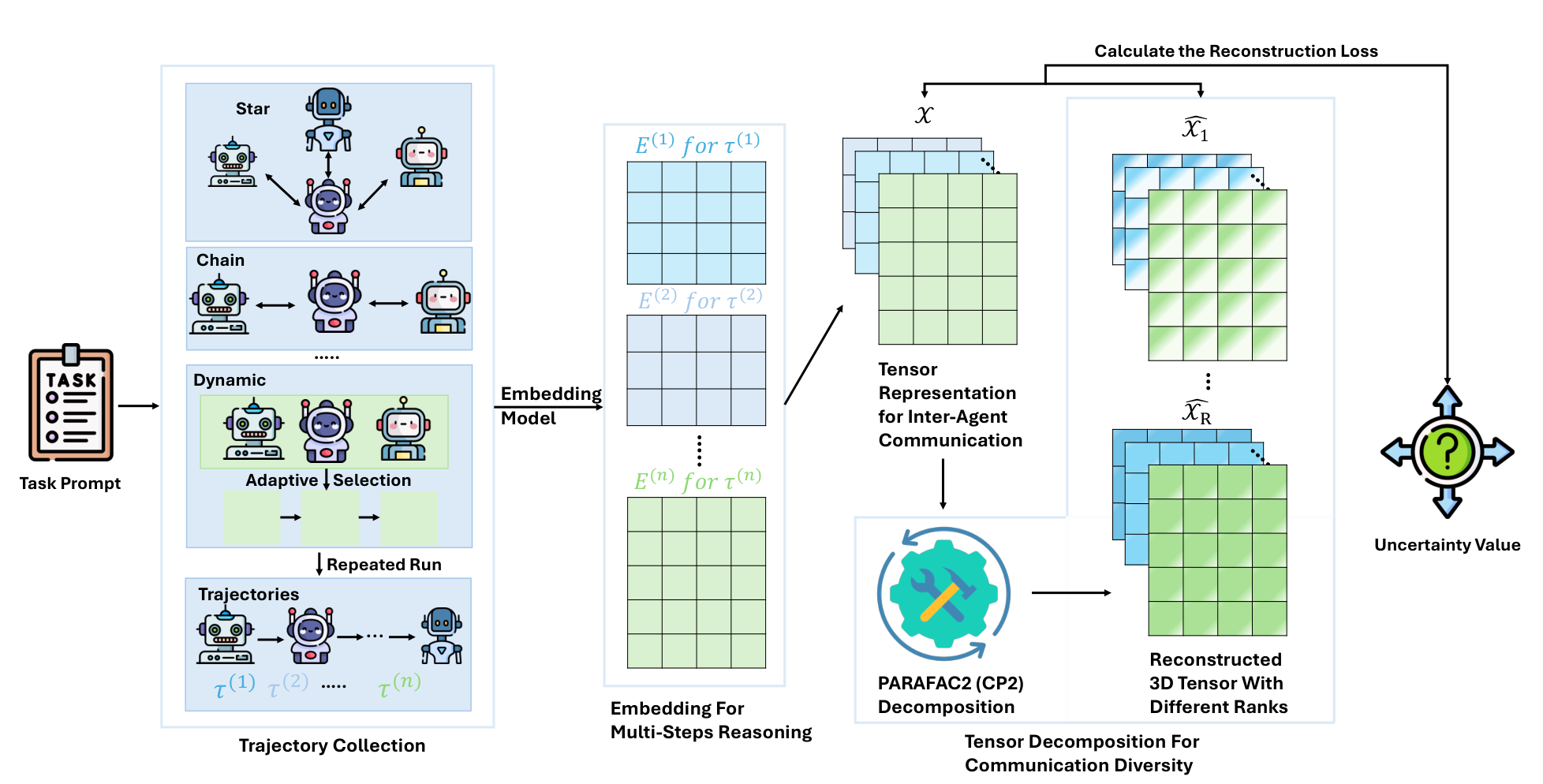 The MATU pipeline turns each run into embedding matrices, stacks them into a ragged tensor over steps, agents, and runs, and reads uncertainty from the reconstruction error of a low-rank decomposition.
The MATU pipeline turns each run into embedding matrices, stacks them into a ragged tensor over steps, agents, and runs, and reads uncertainty from the reconstruction error of a low-rank decomposition.
- Collect the full trajectories. MATU runs the system several times and records every agent’s complete step by step reasoning, including tool calls. A multi-agent failure usually hides in a handoff rather than the final line, so the measurement has to begin from the whole process observed across repeated runs.
- Embed every step. Each step is mapped into a shared embedding space. Raw text cannot be compared directly, but in this space reasoning that means the same thing lands close together, which turns the question of whether the runs thought alike into something we can compute.
- Stack the runs into a ragged tensor. The embedding matrices are arranged along three axes, namely steps, agents, and runs. Trajectories differ in length and come from different roles, so a ragged tensor is used deliberately, because it keeps that shape instead of forcing every run into one mold and erasing the communication patterns that carry the uncertainty.
- Decompose to the shared consensus. A PARAFAC2 decomposition recovers the low rank pattern the runs have in common, which is what the system tends to do. A reliable system sits almost entirely inside this shared structure, so the decomposition is really recovering its expected reasoning.
- Read the leftover residual. Whatever the consensus cannot explain, summed across ranks, becomes the uncertainty score. This residual is the spread of the runs around their own consensus, which is exactly variance, now measured over reasoning trajectories instead of plain numbers.
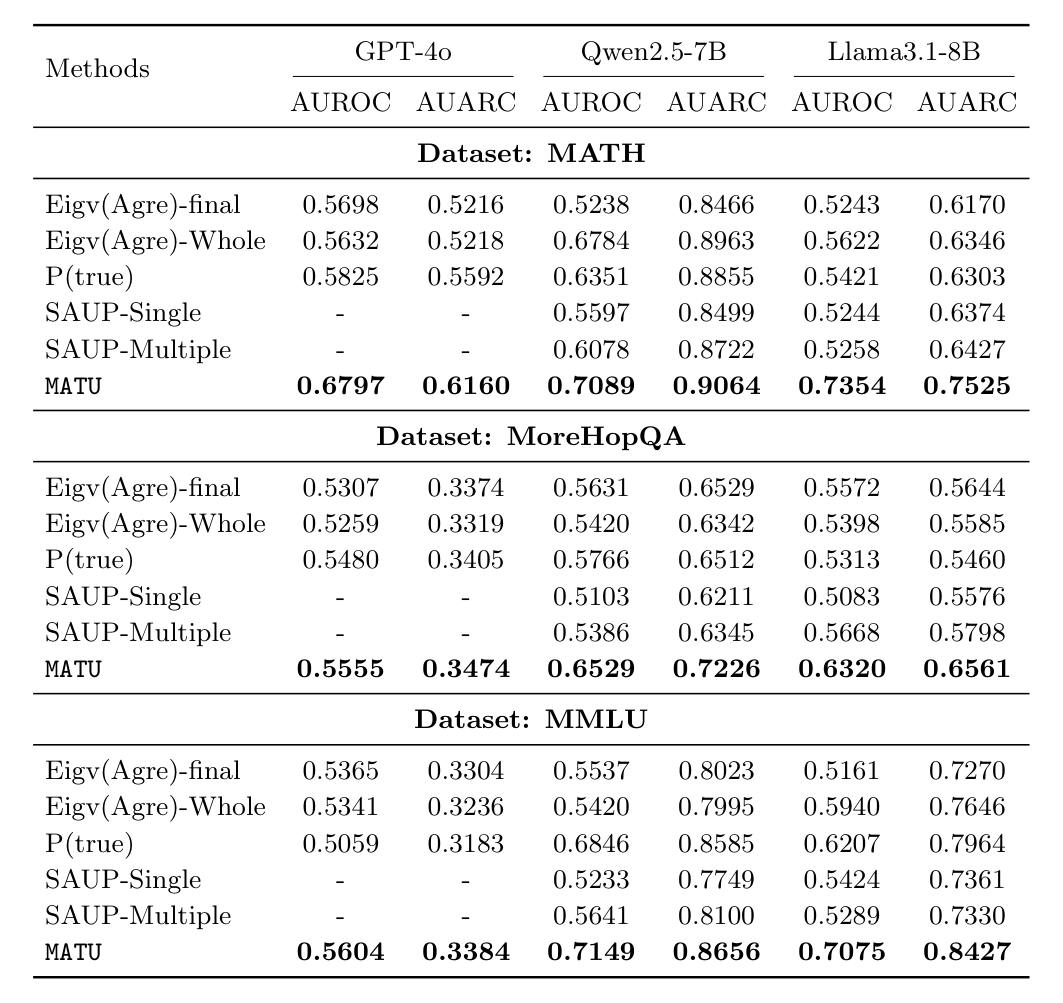
One Score That Holds Across Models and Topologies
Across three multi-agent frameworks, three models, and tasks spanning math, multi-hop QA, and general reasoning, MATU is the most reliable at telling correct runs from incorrect ones.
A case study shows why it wins where others stumble. When every run reaches the right answer but some take a long, verbose path, a length sensitive baseline mistakes that verbosity for doubt and reports high uncertainty, while MATU recognizes that the runs agree in meaning and stays confident. This supports the central claim that reliability should be read from the shared reasoning, not from surface features of the text.
Why It Matters
Reliability in a multi-agent system lives in the whole reasoning process, not the final sentence. Representing that process as a tensor and reading uncertainty from how well it compresses gives one robust score that holds across models, datasets, and communication topologies.