
Uncertainty Quantification and Confidence Calibration in Large Language Models: A Survey
Large language models answer fluently even when they are wrong, so a way to know how much to trust an answer is essential. Uncertainty quantification, the study of estimating a model’s confidence in its own outputs, is that tool. This survey organizes the fast-growing literature on uncertainty quantification for these models and offers a taxonomy that helps a practitioner choose a method. You can read the full paper here.
Why Existing Surveys Fall Short
Classical theory splits uncertainty into two kinds, aleatoric, the irreducible noise in the data, and epistemic, the reducible ignorance of the model. That split was built for small predictive models and misses where uncertainty actually enters a language model, namely an ambiguous prompt, a reasoning chain that can branch, and the randomness of decoding. Earlier surveys either focus narrowly on detecting hallucinations or reuse the old categories, and the traditional estimators they describe, such as training many copies of a model, are far too expensive at this scale. A taxonomy made for language models is needed.
A Taxonomy Built Around the Generation Process
The survey proposes organizing methods along two questions. The first is how much computation a method needs, which ranges from a single forward pass, to drawing many samples, to using an extra model, to fine-tuning the model itself. The second is where the uncertainty comes from in the process of producing an answer. Placing every method on these two axes makes the trade-off between cost and coverage explicit.
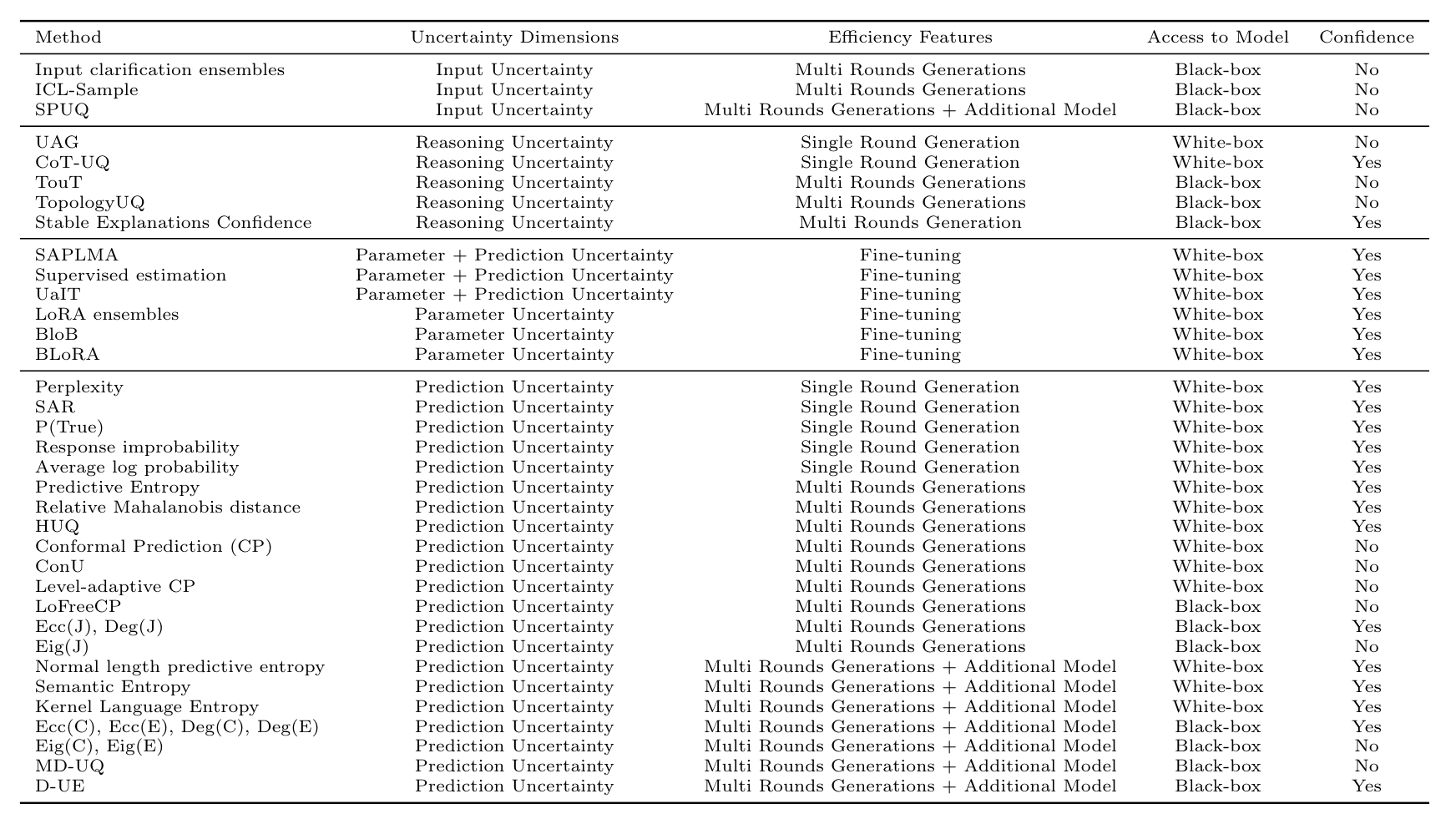 Representative methods summarized along the two taxonomy axes, the source of uncertainty and the computational cost, with model access and whether a method also yields a confidence score shown as extra columns. The table doubles as a quick selection guide.
Representative methods summarized along the two taxonomy axes, the source of uncertainty and the computational cost, with model access and whether a method also yields a confidence score shown as extra columns. The table doubles as a quick selection guide.
The Four Sources of Uncertainty
The second axis names four places uncertainty originates, and the survey reviews methods under each.
- Input uncertainty comes from an ambiguous or underspecified prompt, and is probed by perturbing or rephrasing the input and watching how much the answer changes. The survey notes this source is still understudied.
- Reasoning uncertainty lives in the multi-step chain a model follows, and is tracked by inspecting the steps or the branch points along the way.
- Parameter uncertainty reflects gaps in what the weights actually learned, and is estimated by Bayesian or fine-tuning approaches that the classical, more expensive estimators cannot match at this scale.
- Prediction uncertainty is the variation across generations and is by far the most studied, covering entropy and probability scores, conformal prediction (which returns a set of answers with a coverage guarantee), consistency across samples, and methods that group answers by meaning.
Open Challenges
Five problems stand out. Drawing many samples is expensive for small gains, so cheaper proxies are needed. A single score does not say which of the four sources it came from, so uncertainty should be decoupled and made interpretable. Uncertainty accumulates across the steps of an agent or a long reasoning chain, yet most methods only look at a single output. Evaluation itself is biased, since grading against another model or a simple overlap metric fails to capture meaningful uncertainty such as a confidently wrong answer. And uncertainty across modalities, where image, text, and other inputs must be reconciled, is largely unaddressed for multi-modal models.
Where This Points
Uncertainty in a language model is not one number from one place. Organizing methods by where the uncertainty arises and how much compute they cost turns a crowded field into a usable map, and it makes clear that the cheapest, most interpretable, and best-grounded methods are still to be built.