
Are Classification Robustness and Explanation Robustness Really Strongly Correlated? An Analysis Through Input Loss Landscape
A common belief says that a model robust to adversarial attacks also has robust explanations, since both should come from a flat input loss landscape. This work tests that belief and finds the two are decoupled. You can read the full paper here.
The Challenge: A Widely Assumed Correlation That May Not Hold
If the belief were true, robust classifiers should also have flat explanation loss landscapes and robust saliency maps. The risk is real, because a saliency map can be adversarially manipulated without changing the predicted label, which opens a security gap if the assumed correlation is false.
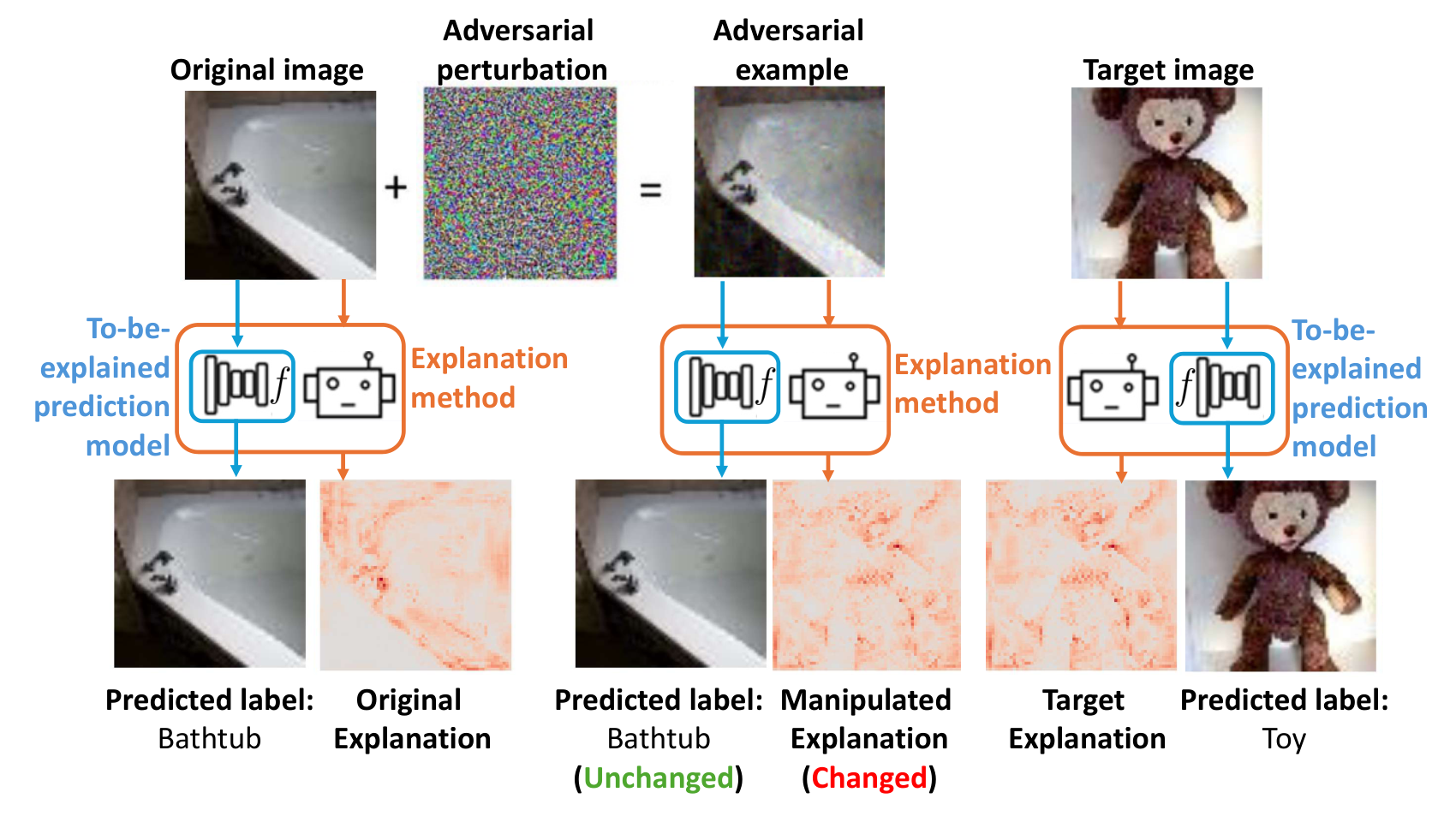 Adding crafted noise leaves the predicted label unchanged yet steers the saliency map toward a target map, which is the manipulation that motivates the study.
Adding crafted noise leaves the predicted label unchanged yet steers the saliency map toward a target map, which is the manipulation that motivates the study.
The Analysis and the SEP Method
The central finding is that classification robustness arises from a flat input loss landscape, but explanation robustness arises mainly from a high starting explanation loss, so flatness turns out to be the wrong lever for explanations.
Span a range of classification robustness
The study first trains many models with a standard trade-off method, sweeping its weight so the models range from weakly to strongly robust against attacks. This sweep is the controlled variable, because to ask whether the two robustness types move together you first need models that differ clearly in classification robustness.
Measure explanation robustness without exploding the cost
Comparing explanations across every pair of inputs is intractable, so the study clusters the data, samples representative prototypes, and measures explanation robustness by how much the explanation still resists being pushed toward a target after an attack converges, where more resistance means more robustness. The motivation is practical, since a tractable yet faithful measurement is what makes a careful comparison possible at all.
Inspect the loss landscape behind each robustness
With those measurements in hand, the study visualizes the input loss landscape of the explanation and checks whether more explanation robustness lines up with a flatter landscape. This is the crux test, because the prevailing belief rests entirely on the assumption that flatness is what drives both kinds of robustness.
Flatten or sharpen on purpose with SEP
Finally the study introduces SEP, a regularizer on the explanation under random noise whose sign decides the effect, flattening the landscape with a positive weight and sharpening it with a negative one. SEP is the causal probe, since being able to move the landscape on demand, while holding the classification training fixed, is what turns a correlation question into a controlled experiment.
The Two Robustness Types Move Independently
Across several datasets and architectures, sharpening the explanation landscape consistently makes explanations harder to attack while flattening it makes them easier, which is the opposite of what the flatness belief predicts, all while classification robustness barely changes.
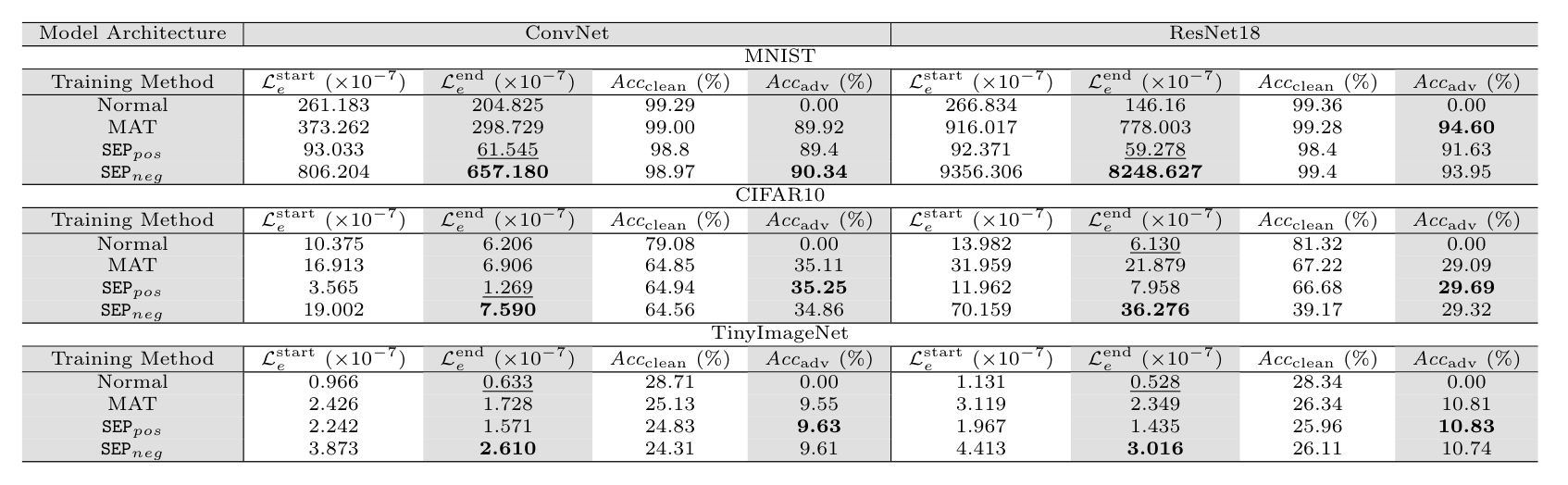
Because explanation robustness can be driven up or down without moving classification robustness, the supposed strong correlation does not hold, and a curvature analysis confirms the effect comes from the landscape itself rather than from any change in accuracy.
Takeaway
Robust classification does not buy robust explanations. Since the two can be moved independently, defending a model’s predictions and defending its explanations are separate goals, and saliency based explanations need their own protection.