
Conformal Feedback Alignment: Quantifying Answer-Level Reliability for Robust LLM Alignment
Aligning a language model with reinforcement learning from AI feedback replaces costly human labels with preferences produced by another model, but that feedback is noisy. This work introduces CFA, which measures how reliable each individual answer is and folds that reliability into the alignment loss. You can read the full paper here.
A Preference Is Only as Good as Its Two Answers
AI-generated preferences are noisy and inconsistent, and prior work copes by weighting the preference, that is by asking how reliable the comparison between two answers is. CFA points at a more basic blind spot, since a comparison between two weak answers tells you very little no matter how carefully you model the comparison itself. The reliability that matters first is the reliability of each answer, and that is what existing methods overlook.
How CFA Scores and Uses Reliability
The guiding idea is to attach a trustworthy reliability score to every answer, then let pairs built on weak answers push the model only gently.
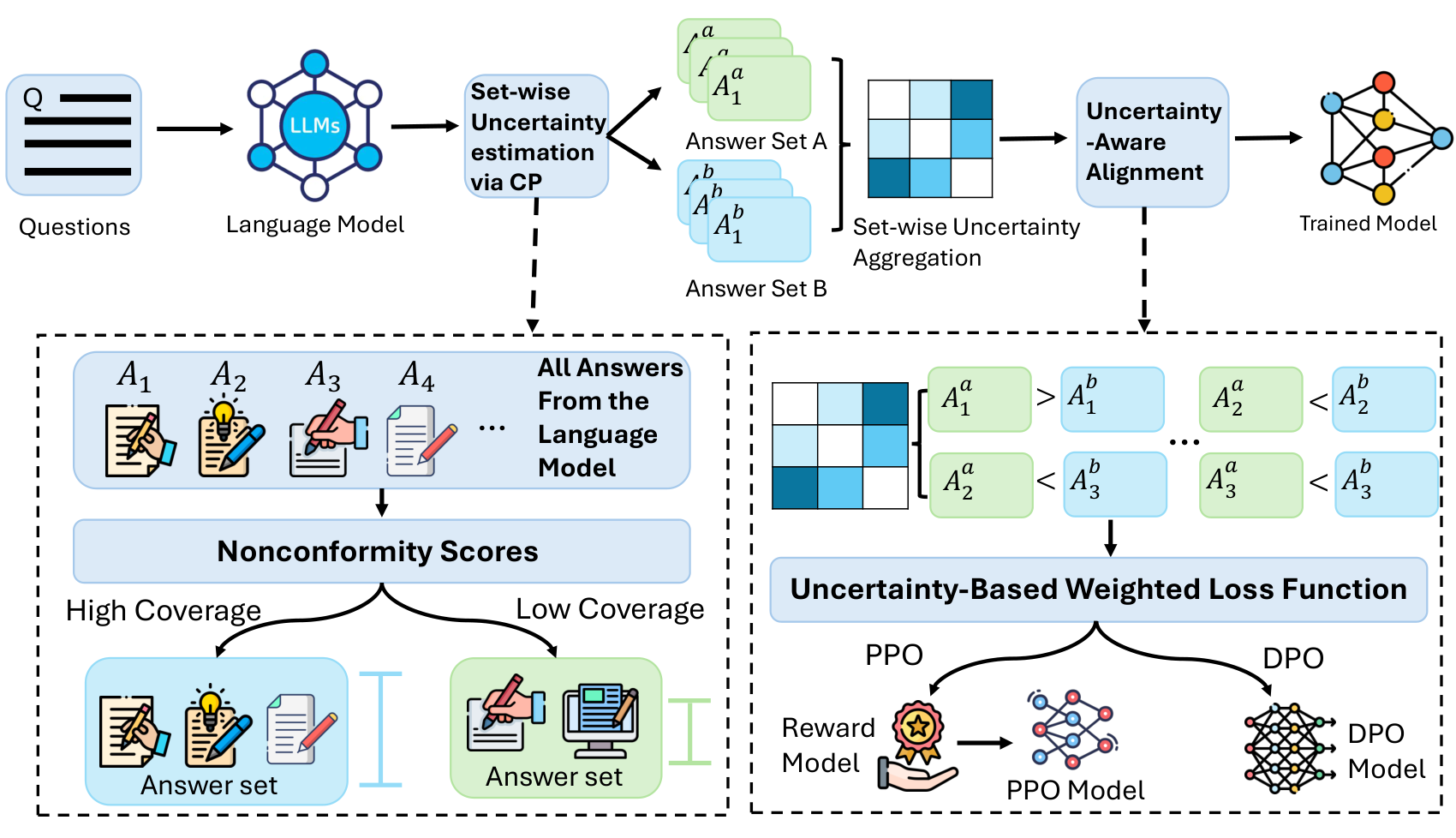 Conformal prediction scores each answer in both black-box and white-box settings, the pair’s set memberships collapse to a single weight, and that weight scales the alignment loss.
Conformal prediction scores each answer in both black-box and white-box settings, the pair’s set memberships collapse to a single weight, and that weight scales the alignment loss.
CFA scores each answer with conformal prediction, a procedure that turns a raw score into a statistically grounded reliability estimate, rather than trusting the model’s self-reported confidence, which is known to be poorly calibrated. When the model’s weights are available it uses the model’s own likelihood, and when they are not it uses a score built from how often a sample recurs and how spread out the samples are. It then forms prediction sets at two coverage levels, which sorts answers into a strongly reliable group and a looser one, so a confident answer can be told apart from one that merely cannot be ruled out. For each preference pair, the two answers’ set memberships collapse into a single weight, high when both answers are reliable and low when either is weak or the two disagree on which group they fall in. That weight finally scales the alignment loss, for both the reward-model and the reward-free style of training, so a pair resting on two shaky answers nudges the policy only slightly while a pair of trustworthy answers counts in full. In effect, noisy feedback becomes soft evidence rather than a hard label.
More Reliable Alignment from the Same Feedback
Across three models, three datasets, and both styles of alignment, CFA improves on the standard alignment every single time, which shows that down-weighting unreliable pairs helps regardless of the setup.
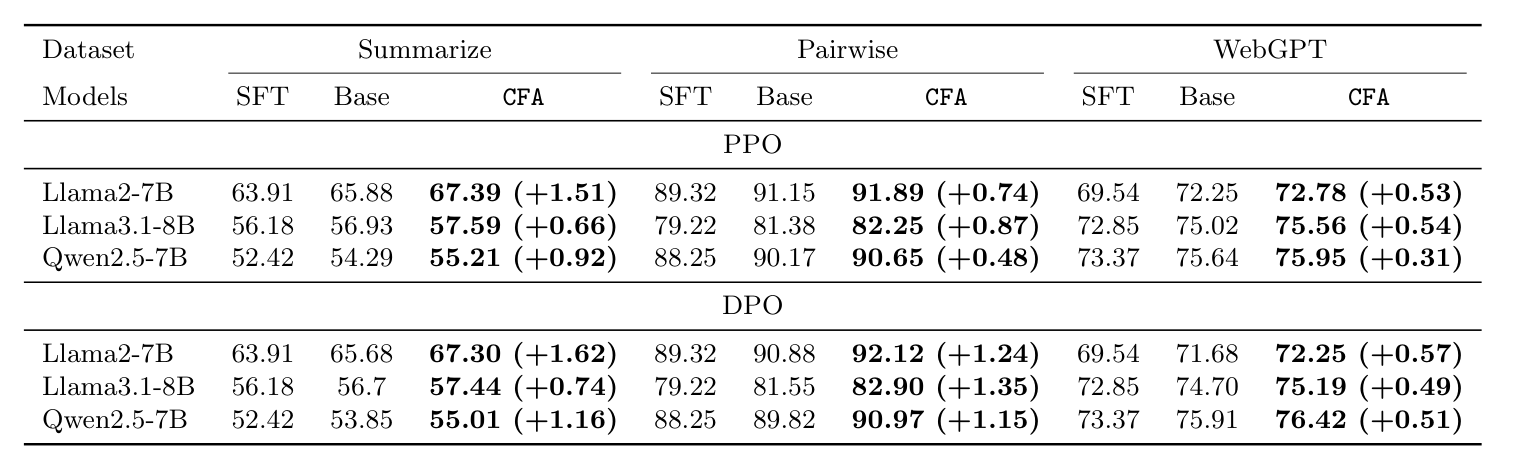
In its best case the improvement is on the same scale as what the standard alignment itself adds over plain fine-tuning, and CFA compares favorably with methods that weight the preference rather than the answers. Both results back the central claim that reliability is best measured at the answer level.
Takeaway
Noisy AI feedback is partly a data quality problem at the source. Measuring how reliable each answer is, then weighting the learning signal by it, makes alignment more robust and more data efficient than weighting the preference alone.